챕터 7 2호선 지하철 혼잡도 분석
서울 지하철은 붐빈다. 자리도 없고 혼잡한 승차 시간엔 더 불편하다. 하지만, 이를 피하기 위한 작은 전략들이 있다. 아주 일찍 나가거나 늦게 가는 방법이다. 그렇다면 ‘정확히’ 어느 시간에 가면될까? 마침 datatoys패키지에는 busyMetro데이터셋이 내장되어있다. 이는 서울교통공사 1-8호선 30분 단위 평균 혼잡도로 30분간 지나는 열차들의 평균 혼잡도(정원대비 승차인원)를 의미한다.
## Warning in str(busyMetro): restarting interrupted promise evaluation## tibble [64,662 × 7] (S3: tbl_df/tbl/data.frame)
## $ 요일구분: chr [1:64662] "평일" "평일" "평일" "평일" ...
## $ 호선 : int [1:64662] 1 1 1 1 1 1 1 1 1 1 ...
## $ 역번호 : int [1:64662] 150 150 150 150 150 150 150 150 150 150 ...
## $ 출발역 : chr [1:64662] "서울역" "서울역" "서울역" "서울역" ...
## $ 상하구분: chr [1:64662] "상선" "상선" "상선" "상선" ...
## $ 시간 : Factor w/ 39 levels "5:30","6:00",..: 1 2 3 4 5 6 7 8 9 10 ...
## $ 혼잡도 : num [1:64662] 7.3 18.1 18.1 30.9 56.6 69.1 82.7 57.5 52.3 36.9 ...먼저 시간별로 전체 지하철의 혼잡도를 살펴보자.
## # A tibble: 39 × 2
## 시간 평균혼잡도
## <fct> <dbl>
## 1 5:30 14.8
## 2 6:00 14.7
## 3 6:30 14.3
## 4 7:00 18.6
## 5 7:30 24.5
## 6 8:00 32.1
## 7 8:30 30.0
## 8 9:00 29.3
## 9 9:30 27.7
## 10 10:00 25.6
## # … with 29 more rows혼잡도를 그래프로 나타내 보면 다음과 같다. geom_line() 함수 안에 aes(group = 1)을 추가하여 모든 데이터 요소를 하나의 그룹으로 처리할 수 있다.
busyMetro %>%
group_by(시간) %>%
summarise(평균혼잡도 = mean(혼잡도, na.rm = TRUE)) %>%
ggplot(aes(시간, 평균혼잡도)) +
geom_line(aes(group = 1)) +
labs(title = "서울교통공사 지하철 시간대별 평균 혼잡도", subtitle = "평일 05:30 ~ 00:30")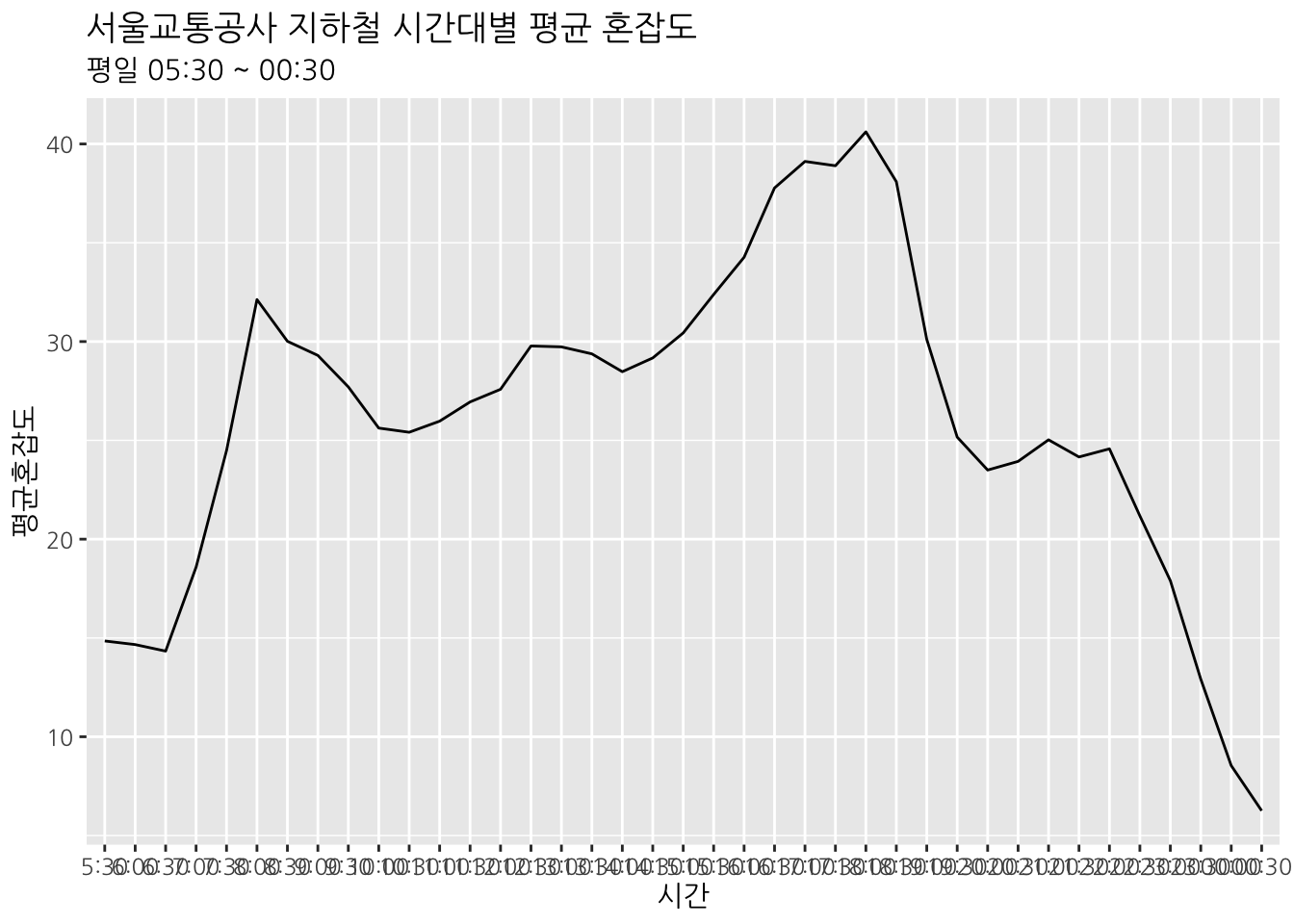
화면비율이나 크기에 따라 다르겠지만, x축의 시간 변수가 겹쳐보인다. 이를 해결하기 위해 x축의 글자들을 45도 회전시켜보자.theme() 함수 안에 axis.text.x = element_text(angle = 45, hjust = 1)을 추가하면 된다. hjust =를 사용해서 높이를 약간 조절해준다.
busyMetro %>%
group_by(시간) %>%
summarise(평균혼잡도 = mean(혼잡도, na.rm = TRUE)) %>%
ggplot(aes(시간, 평균혼잡도)) +
geom_line(aes(group = 1)) +
labs(title = "서울교통공사 지하철 시간대별 평균 혼잡도", subtitle = "평일 05:30 ~ 00:30") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))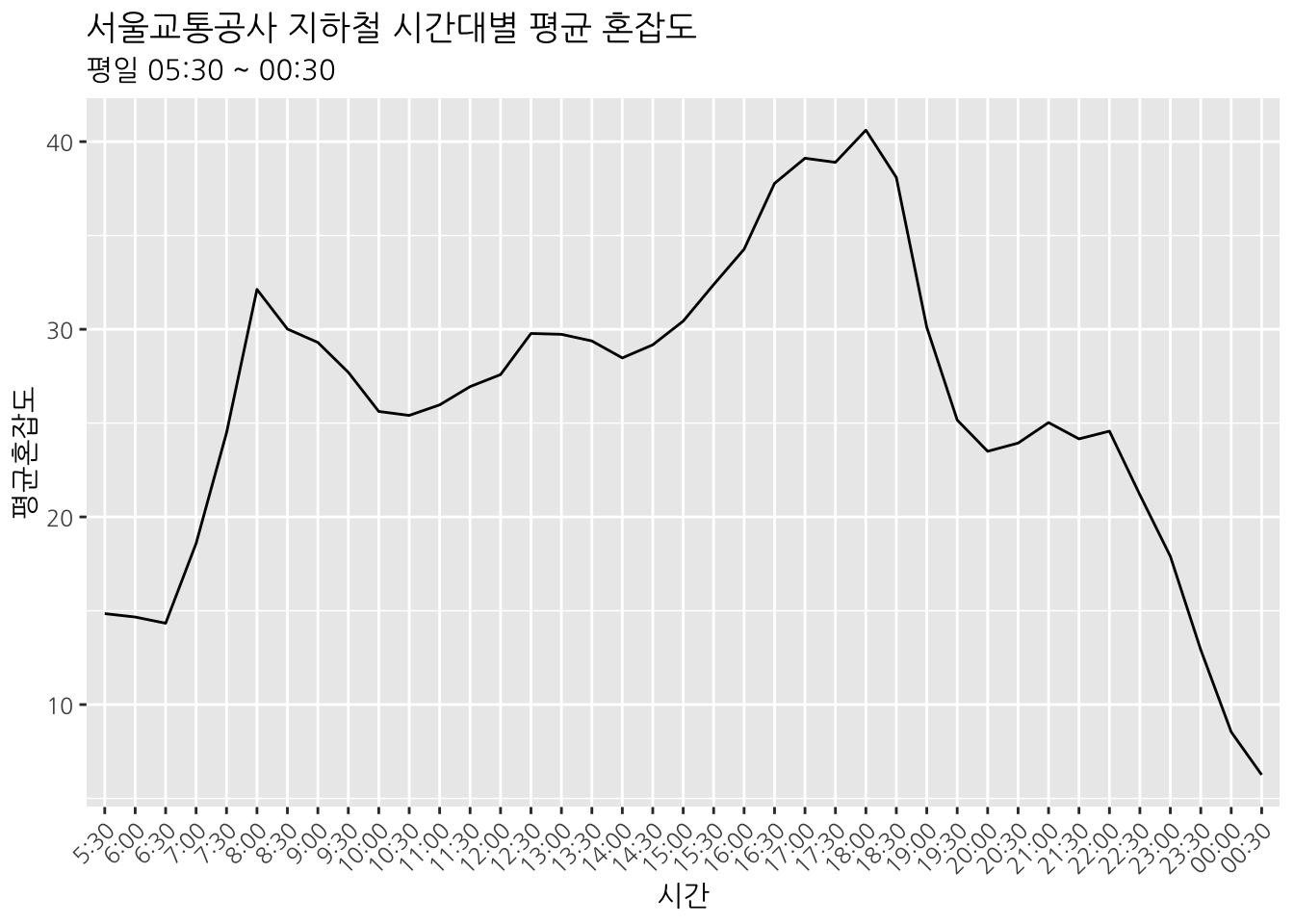
확실히 출근시간과 퇴근시간 대에 피크를 볼 수 있다. 그렇다면 평일과 주말의 양상은 어떻게 다를까? geom_line() 함수 안에 aes(color = 요일구분)을 추가하면 요일별로 색상을 다르게 표현할 수 있다. scale_color_manual() 함수를 이용해 색상을 직접 지정할 수도 있다.
busyMetro %>%
group_by(요일구분, 시간) %>%
summarise(평균혼잡도 = mean(혼잡도, na.rm = TRUE)) %>%
ggplot(aes(시간, 평균혼잡도)) +
geom_line(aes(group = 요일구분, color = 요일구분)) +
scale_color_manual(values = c("#E966A0", "#213363", "#8EAC50")) +
labs(title = "서울교통공사 지하철 시간대별 평균 혼잡도", subtitle = "평일 05:30 ~ 00:30") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))## `summarise()` has grouped output by '요일구분'. You can override using the `.groups` argument.## Warning: Removed 4 rows containing missing values (`geom_line()`).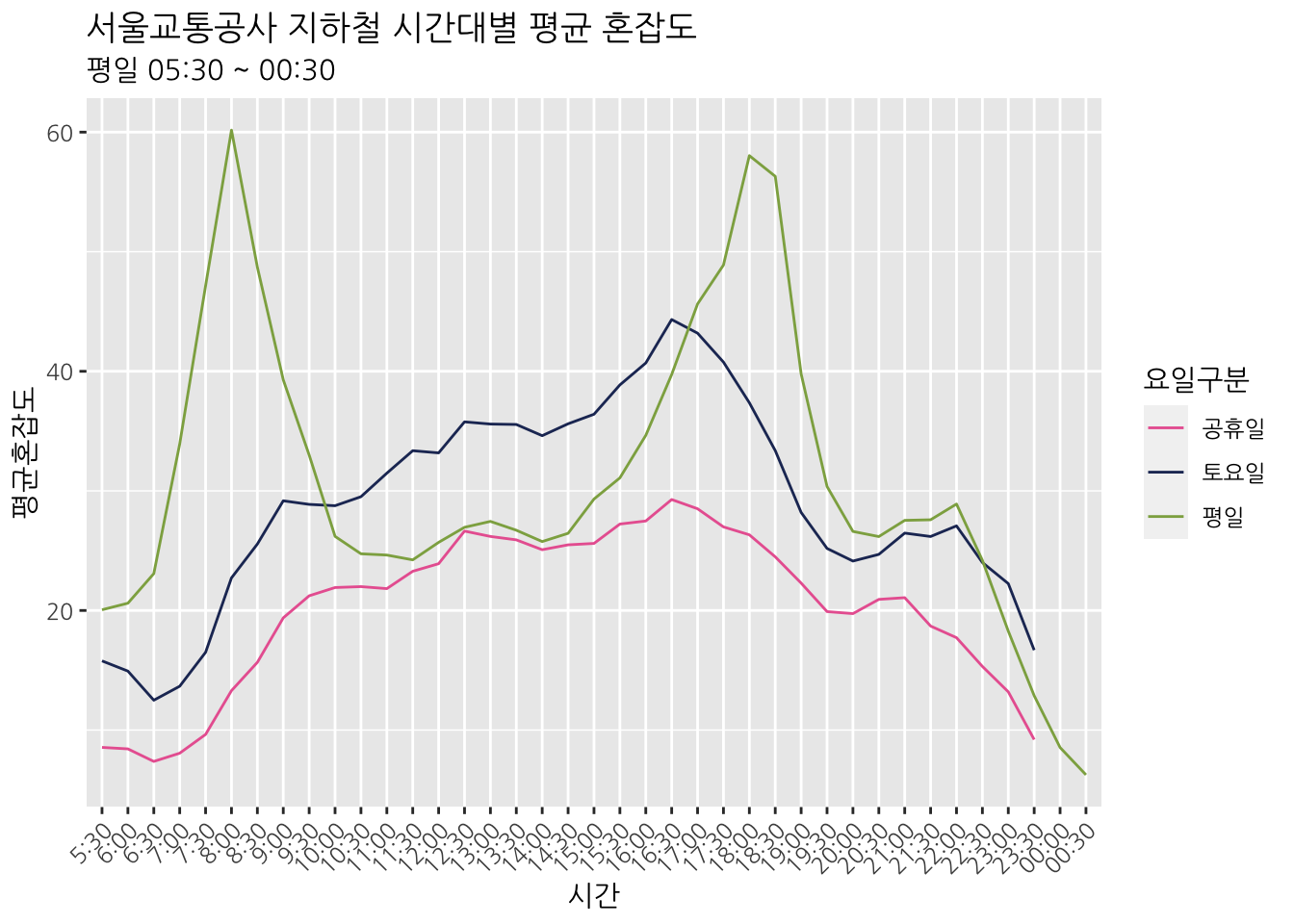
## Warning: Removed 4 rows containing missing values geom_line().라는 경고문구가 나타난다. 주말이나 공휴일에는 지하철 운행시간이 달라 데이터가 존재하지 않기 때문이다. legend 위치를 조절하기 위해서는 theme() 함수 안에 legend.position =을 추가하면 된다.
busyMetro %>%
group_by(요일구분, 시간) %>%
summarise(평균혼잡도 = mean(혼잡도, na.rm = TRUE)) %>%
ggplot(aes(시간, 평균혼잡도)) +
geom_line(aes(group = 요일구분, color = 요일구분)) +
scale_color_manual(values = c("#E966A0", "#213363", "#8EAC50")) +
labs(title = "서울교통공사 지하철 시간대별 평균 혼잡도", subtitle = "평일 05:30 ~ 00:30") +
theme(
axis.text.x = element_text(angle = 45, hjust = 1),
legend.position = "bottom"
)## `summarise()` has grouped output by '요일구분'. You can override using the `.groups` argument.## Warning: Removed 4 rows containing missing values (`geom_line()`).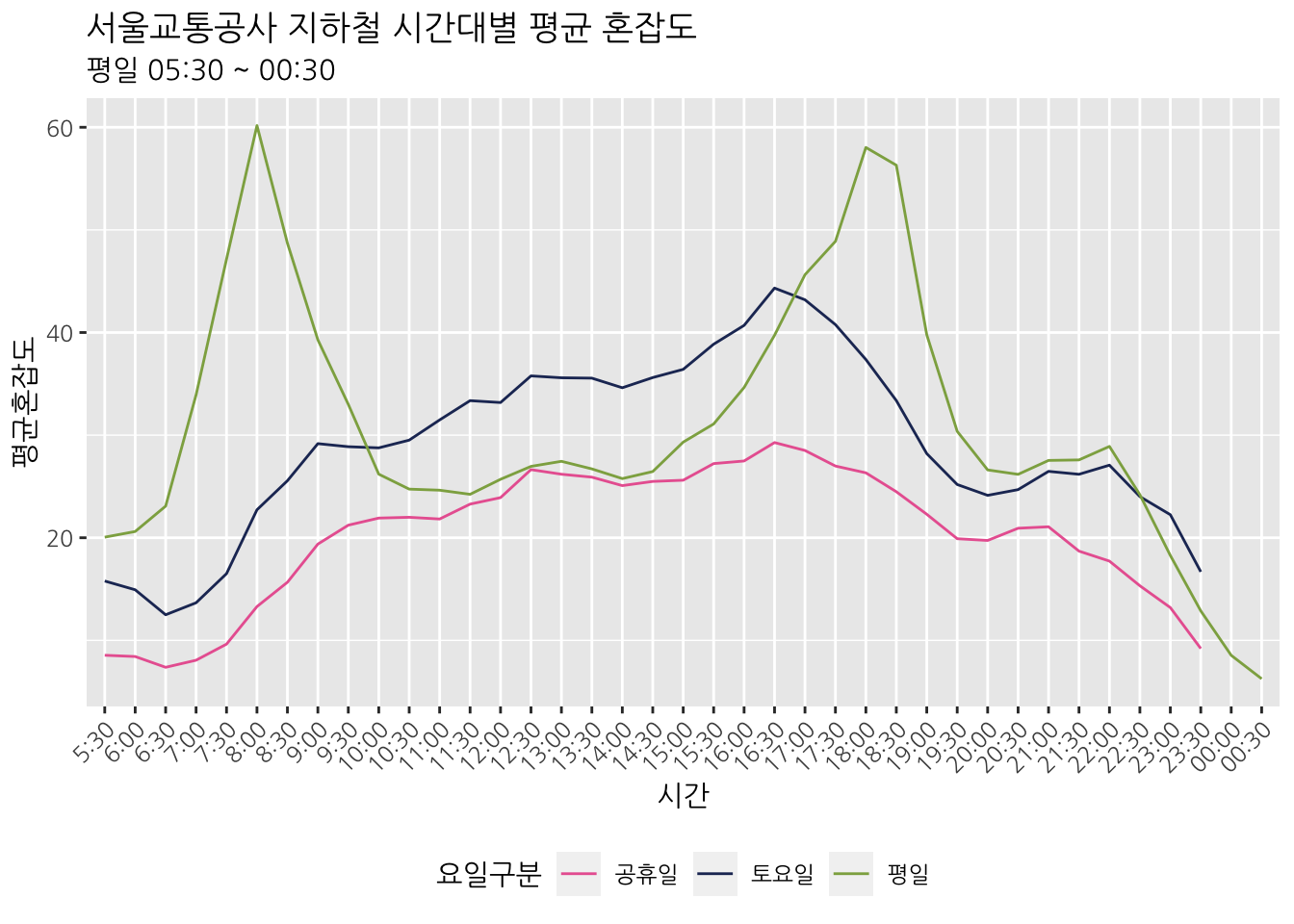
이번에는 호선별로 평일 지하철 혼잡도를 살펴보자. facet_wrap() 함수를 이용하면 호선별로 그래프를 나눌 수 있다. facet_wrap() 함수 안에 . ~호선을 추가하면 호선별로 그래프를 나눌 수 있다. strip.position = "bottom"을 추가하면 그래프의 하단에 호선명이 나타난다.
busyMetro %>%
filter(요일구분 == "평일") %>%
group_by(호선, 시간) %>%
summarise(평균혼잡도 = mean(혼잡도, na.rm = TRUE)) %>%
ggplot(aes(시간, 평균혼잡도)) +
geom_line(aes(group = 1)) +
facet_wrap(. ~호선, ncol = 2, strip.position = "top") +
labs(title = "서울교통공사 지하철 시간대별 혼잡도", subtitle = "평일 05:30 ~ 00:30") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))## `summarise()` has grouped output by '호선'. You can override using the `.groups` argument.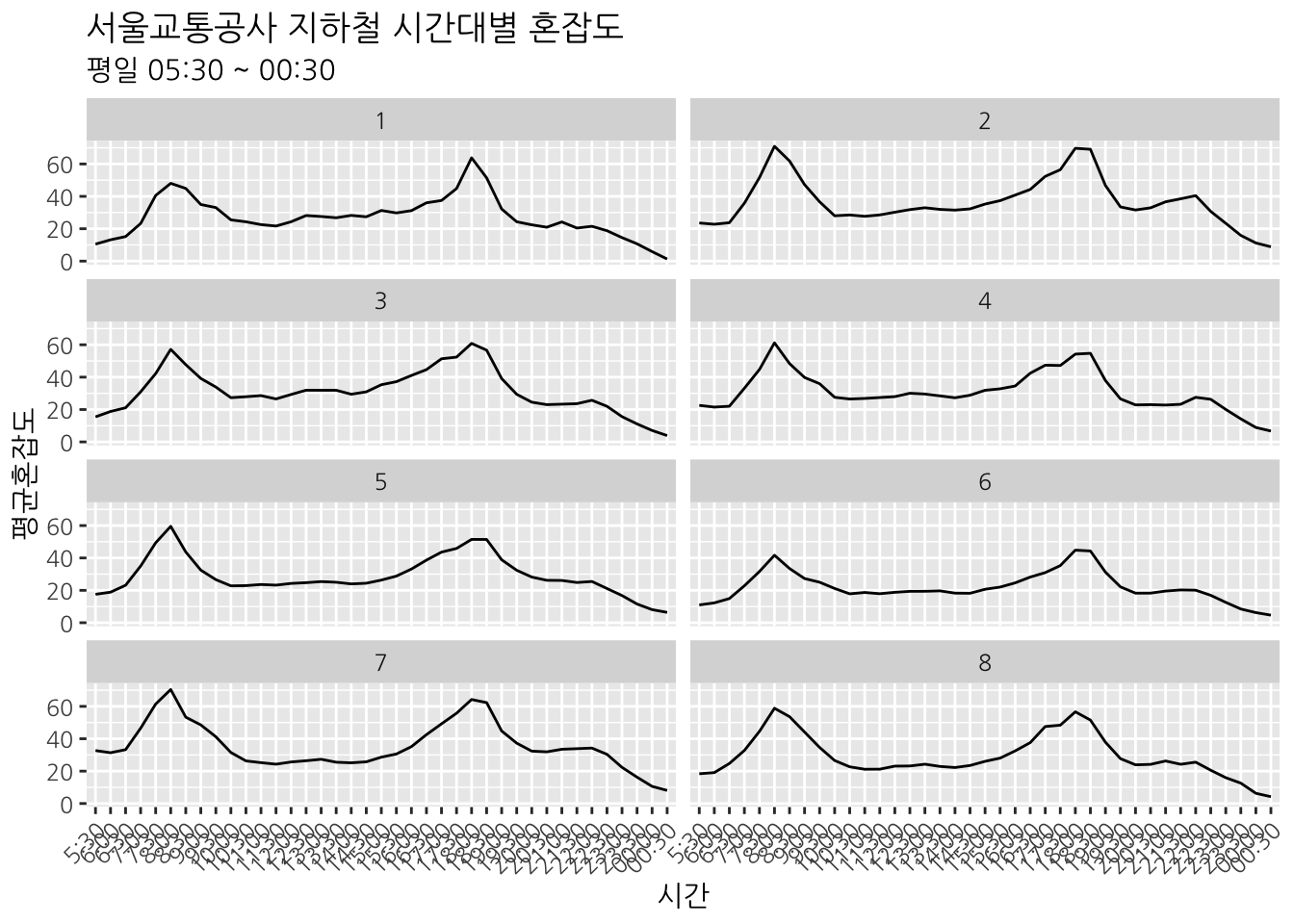
가장 붐비는 지하철 역은 어딜까?
very_busy <- busyMetro %>%
filter(요일구분 == "평일") %>%
group_by(출발역, 상하구분) %>%
summarise(평균혼잡도 = mean(혼잡도, na.rm = TRUE)) %>%
arrange(desc(평균혼잡도)) %>%
head(20)## `summarise()` has grouped output by '출발역'. You can override using the `.groups` argument.## # A tibble: 20 × 3
## # Groups: 출발역 [13]
## 출발역 상하구분 평균혼잡도
## <chr> <chr> <dbl>
## 1 방배 내선 58.1
## 2 교대 내선 57.6
## 3 서초 내선 57.5
## 4 석촌 하선 56.4
## 5 송파 상선 55.8
## 6 강남 내선 55.7
## 7 송파 하선 54.6
## 8 사당 내선 54.4
## 9 서초 외선 54.0
## 10 사당 외선 53.8
## 11 방배 외선 53.5
## 12 교대 외선 53.2
## 13 어린이대공원 하선 52.4
## 14 건대입구 상선 52.0
## 15 잠실 하선 51.8
## 16 낙성대 내선 51.8
## 17 문정 상선 51.5
## 18 석촌 상선 51.5
## 19 어린이대공원 상선 51.0
## 20 역삼 내선 50.9평일 평균 혼잡도가 가장 높은 상위 20개 역을 선정하였다. 그럼 각 역의 시간대별 혼잡도를 살펴보자. filter() 함수를 이용해 평일 데이터만 추출하고, mutate() 함수를 이용해 출발역 변수를 생성한다. paste() 함수를 이용해 호선, 상하구분과 출발역을 붙여주었다. facet_wrap() 함수를 이용해 출발역별로 그래프를 나누었다. element_blank()를 사용하면 축의 텍스트를 제거할 수 있다.
very_busy %>%
select(출발역, 상하구분) %>%
left_join(busyMetro, by = c("출발역", "상하구분")) %>%
filter(요일구분 == "평일") %>%
mutate(출발역 = paste(호선, "호선", 출발역, 상하구분)) %>%
ggplot(aes(시간, 혼잡도, color = 상하구분)) +
geom_line(aes(group = 상하구분)) +
facet_wrap(. ~출발역, ncol = 5, strip.position = "bottom") +
labs(
title = "서울교통공사 지하철 시간대별 혼잡도",
subtitle = "상위 20개 역; 평일 05:30 ~ 00:30"
) +
theme(axis.text.x = element_blank())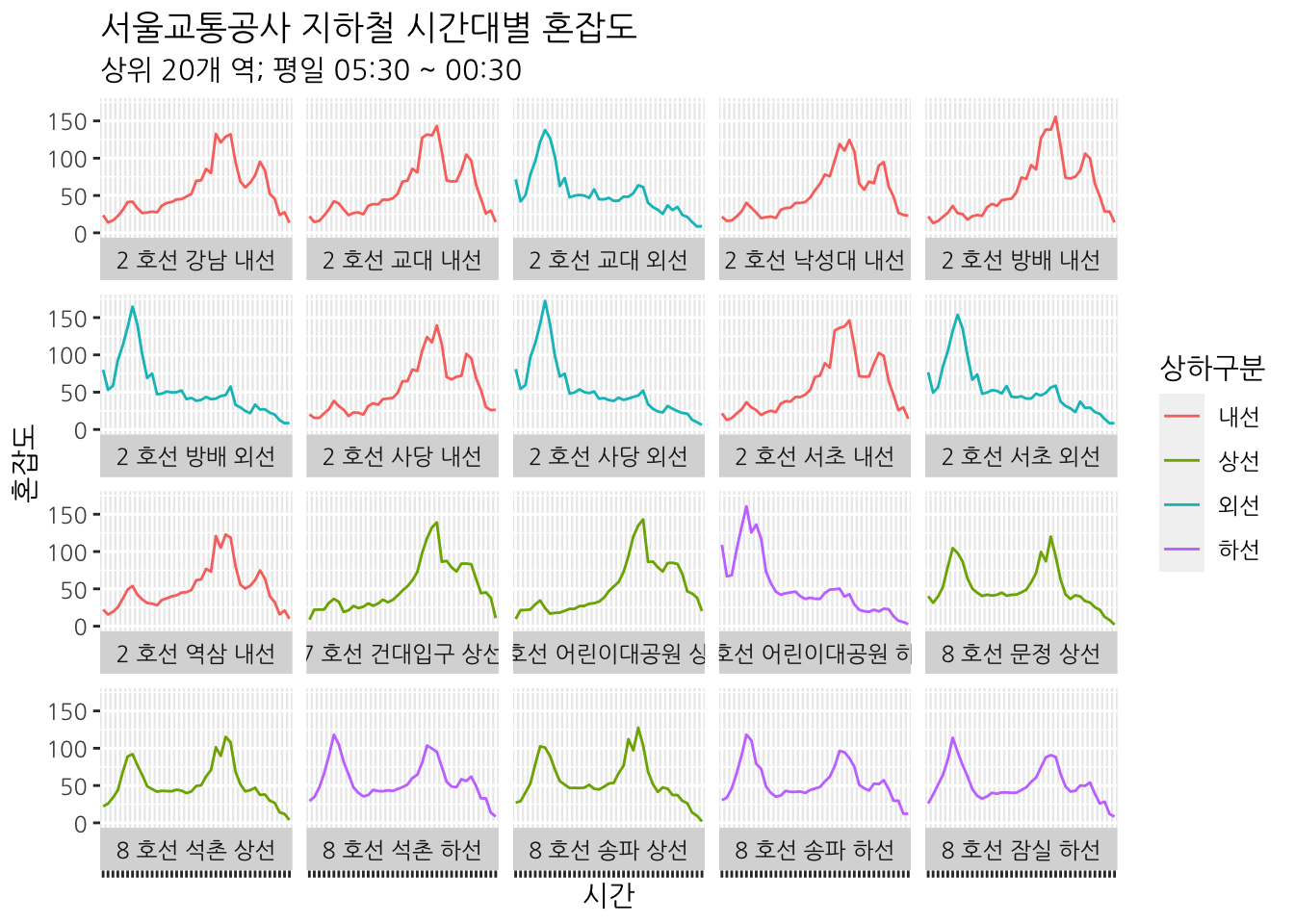
평일 붐비는 지하철이 싫다면, 저 시간대를 피하거나 다른 경로를 이용해 보는건 어떨까?