챕터 5 시각화 기초
데이터 시각화는 데이터를 시각적으로 표현하여 이를 이해하고 전달하는 데에 사용된다. 숫자로만 이뤄진 복잡한 데이터를 직관적이고 효과적으로 분석할 수 있으며, 트렌드, 패턴, 상관 관계 등을 시각적으로 파악할 수 있다. 이런 시각화는 데이터를 보다 직관적으로 이해할 수 있도록 하여 데이터를 통한 의사소통을 원활하게 할 수 있다. 시각화는 결국 ‘효과적인 정보 전달’이 목적인데 그러기 위해서는 사람의 인지방식에 대한 이해 또한 필요하다. 한마디로 데이터 시각화란 데이터에서 찾은 인사이트를 사람이 쉽게 인지할 수 있게 표현하는 방법이다.
여기 앤스컴 콰르탯이라는 데이터가 존재한다(datasets 패키지에 내장되어 있다). 영국의 통계학자인 Frank Anscombe이 만든 데이터셋들로 X1~X4, Y1~Y4까지 데이터가 존재하며 각각 숫자에 맞는 X와 Y값은 매칭되는 총 4개의 그룹에 각각 11개의 관측값이 존재하는 데이터다.
| x1 | x2 | x3 | x4 | y1 | y2 | y3 | y4 |
|---|---|---|---|---|---|---|---|
| 10 | 10 | 10 | 8 | 8.04 | 9.14 | 7.46 | 6.58 |
| 8 | 8 | 8 | 8 | 6.95 | 8.14 | 6.77 | 5.76 |
| 13 | 13 | 13 | 8 | 7.58 | 8.74 | 12.74 | 7.71 |
| 9 | 9 | 9 | 8 | 8.81 | 8.77 | 7.11 | 8.84 |
| 11 | 11 | 11 | 8 | 8.33 | 9.26 | 7.81 | 8.47 |
| 14 | 14 | 14 | 8 | 9.96 | 8.10 | 8.84 | 7.04 |
| 6 | 6 | 6 | 8 | 7.24 | 6.13 | 6.08 | 5.25 |
| 4 | 4 | 4 | 19 | 4.26 | 3.10 | 5.39 | 12.50 |
| 12 | 12 | 12 | 8 | 10.84 | 9.13 | 8.15 | 5.56 |
| 7 | 7 | 7 | 8 | 4.82 | 7.26 | 6.42 | 7.91 |
| 5 | 5 | 5 | 8 | 5.68 | 4.74 | 5.73 | 6.89 |
나열된 숫자만을 읽는 것은 매우 피곤한일인지라, 먼저 데이터의 평균과 분산을 한번 계산해보자(코드의 해석은 생각하지 말고 결과값에 집중해보자).
## $x1
## [1] 9
##
## $x2
## [1] 9
##
## $x3
## [1] 9
##
## $x4
## [1] 9
##
## $y1
## [1] 7.500909
##
## $y2
## [1] 7.500909
##
## $y3
## [1] 7.5
##
## $y4
## [1] 7.500909## $x1
## [1] 11
##
## $x2
## [1] 11
##
## $x3
## [1] 11
##
## $x4
## [1] 11
##
## $y1
## [1] 4.127269
##
## $y2
## [1] 4.127629
##
## $y3
## [1] 4.12262
##
## $y4
## [1] 4.123249X1~X4 모두 평균 9, 분산 11로 동일했으며, Y1~Y4 에서도 평균 7.5 분산 4.12로 동일했다.
## x1 x2 x3 x4 y1 y2 y3 y4
## x1 1.0000000 1.0000000 1.0000000 -0.5000000 0.8164205 0.8162365 0.8162867 -0.3140467
## x2 1.0000000 1.0000000 1.0000000 -0.5000000 0.8164205 0.8162365 0.8162867 -0.3140467
## x3 1.0000000 1.0000000 1.0000000 -0.5000000 0.8164205 0.8162365 0.8162867 -0.3140467
## x4 -0.5000000 -0.5000000 -0.5000000 1.0000000 -0.5290927 -0.7184365 -0.3446610 0.8165214
## y1 0.8164205 0.8164205 0.8164205 -0.5290927 1.0000000 0.7500054 0.4687167 -0.4891162
## y2 0.8162365 0.8162365 0.8162365 -0.7184365 0.7500054 1.0000000 0.5879193 -0.4780949
## y3 0.8162867 0.8162867 0.8162867 -0.3446610 0.4687167 0.5879193 1.0000000 -0.1554718
## y4 -0.3140467 -0.3140467 -0.3140467 0.8165214 -0.4891162 -0.4780949 -0.1554718 1.0000000X와 매칭되는 Y의 상관계수는 각각 0.816으로 동일했으며 1차 회귀식은 모두 y = 3 + 0.5x로 동일했다. 즉 4개 그룹의 평균, 분산, 상관계수 및 회귀식이 모두 같다. 이것만 보면 같은 경향을 가진 데이터로 볼 수 있을 것이다. 하지만 이 데이터들을 산포도 표시하면 어떤 결과가 나타날까? 역시 코드의 해석은 생각하지 말고 결과값에 집중해보자.
par(mfrow = c(2, 2)) # 그래프를 2x2 그리드로 배치
# 첫 번째 그래프
plot(anscombe$x1, anscombe$y1, main = "Group I",
xlab = "x", ylab = "y")
# 두 번째 그래프
plot(anscombe$x2, anscombe$y2, main = "Group II",
xlab = "x", ylab = "y")
# 세 번째 그래프
plot(anscombe$x3, anscombe$y3, main = "Group III",
xlab = "x", ylab = "y")
# 네 번째 그래프
plot(anscombe$x4, anscombe$y4, main = "Group IV",
xlab = "x", ylab = "y")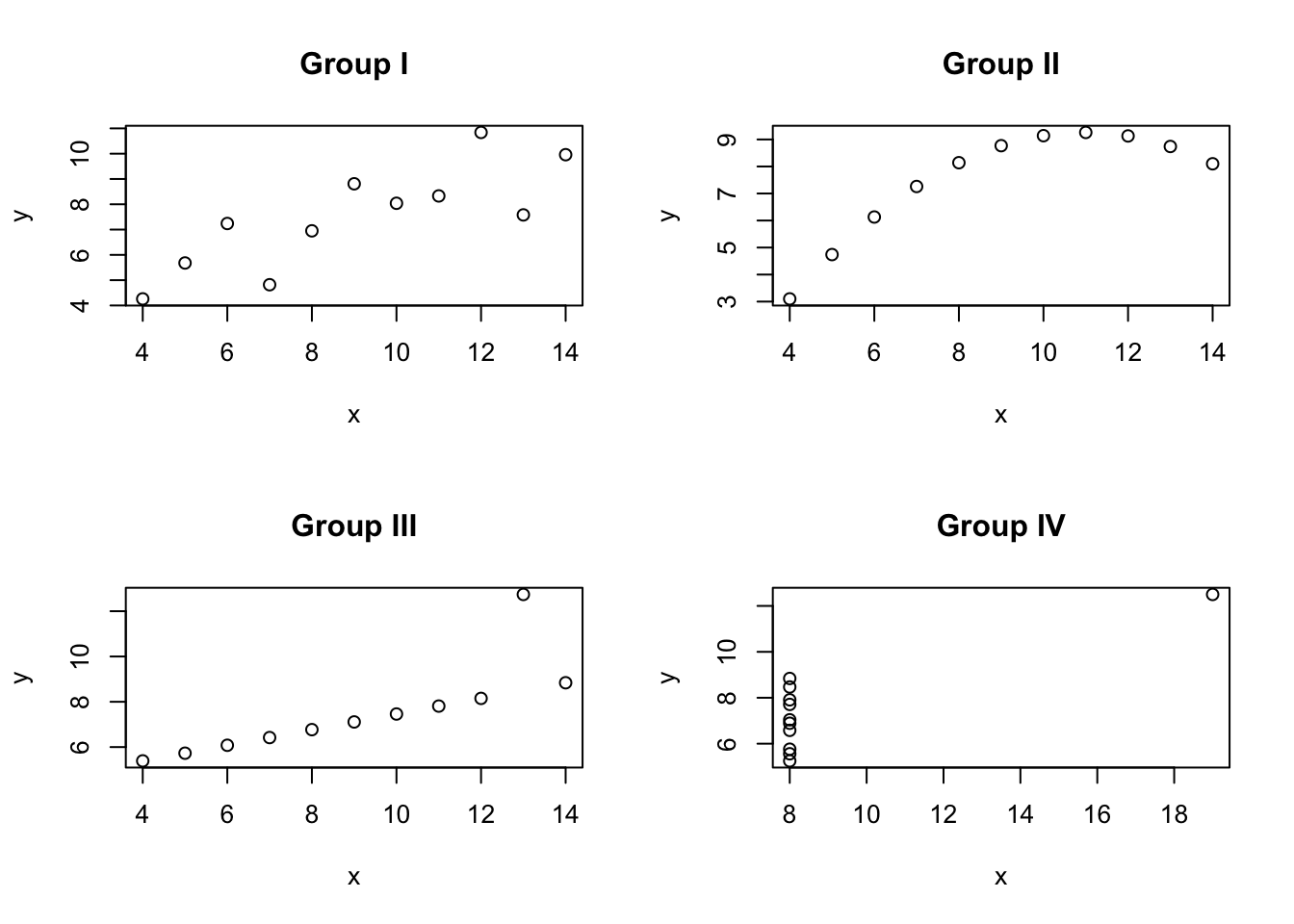
각 그룹은 평균, 분산, 상관관계, 회귀선 등의 통계적 속성이 거의 동일하지만 시각화해보면 각 그룹이 실제로 매우 다른 패턴을 갖고 있음을 알 수 있다. 시각적인 표현은 복잡한 데이터를 이해하기 쉽고 직관적으로 만들어준다. 앤스컴 콰르탯 데이터셋을 예시로 들어 설명했지만, 실제 데이터에서도 시각화를 통해 통찰력을 얻고 결정을 내릴 수 있을 것이다. 다음은 데이터 시각화를 하는 대표적인 이유들이다.
패턴 식별: 데이터 시각화는 데이터의 패턴을 식별하는 데 도움이 된다. 이렇게 패턴을 인식하는 것은 데이터를 이해하고 향후 분석에 활용하는 데 중요하다.
이상치 탐지: 데이터 시각화는 이상치를 탐지하는 데 유용하다. 이상치는 데이터셋에서 일반적인 패턴과 다른 값을 가진 데이터 포인트를 의미하는데, 앤스컴 콰르탯 데이터셋의 경우, 그룹 3의 x = 13, y = 12.74와 같은 값이나 그룹 4에서 x = 19, y = 12.50과 같은 이상치를 쉽게 식별할 수 있다. 이렇게 이상치를 시각적으로 확인하면 데이터의 신뢰성과 정확성을 평가할 수 있다.
상관관계 이해: 데이터 시각화는 변수 간의 상관관계를 시각적으로 이해하는 데 도움이 된다. 앤스컴 콰르탯 데이터셋의 그룹 1의 경우 x와 y의 관계가 비선형적이고 종 모양의 패턴을 보여주고, 그룹 2를 보면 선형적인 상관관계가 있음을 쉽게 알 수 있다. 이러한 상관관계를 시각화하여 변수 간의 관계를 파악하면 추세를 예측하고 의사 결정을 내릴 수 있다.
5.1 이왕이면 예쁜 그래프
같은 값이면 다홍치마 – 우리속담
심미적 사용성 효과(Aesthetic-Usability Effect)에 따르면, 심미적인 디자인은 사람들의 두뇌에 긍정적인 반응을 불러일으키고 디자인이 실제로 더 잘 작동한다고 믿게 만든다고 한다. 심미적인 디자인은 데이터의 패턴과 관계를 뚜렷하게 시각화하여 전달력을 강화한다. 그래프의 색상, 레이아웃, 텍스트의 크기와 스타일 등을 조절하여 데이터의 중요한 부분을 강조하거나, 시각적인 잡음을 최소화 함으로 보는이가 데이터의 핵심 메시지를 빠르게 파악하고 이해하는 데 도움을 줄 수 있다. 심미적인 데이터 시각화는 창의성과 상상력을 자극하기도 한다. 예술적인 요소를 활용한 시각화는 데이터에 새로운 시각을 부여함으로 새로운 통찰력을 발견할 수 있게 한다. 무엇보다 예쁜 디자인은 사람들의 관심을 끌어 더 많은 사람들에게 도달하고 공유될 수 있다. 어색하게 느껴질 수 도 있지만 데이터 시각화를 위해서는 심리학과 인문학이 중요하다. 바로 사람이 어떻게 세상을 보고 해석하는지에 대한 깊은 이해를 기반으로 한다는 공통점이 있기 때문이다. UX 디자인 분야로 생각할 수도 있겠지만 Jon Yablonski가 제작한 Law of UX 웹페이지에는 사용자 경험 디자인과 관련된 심리학적 이론을 수집하여 매력적인 디자인 방법을 소개한다.
5.2 시각화 요소
5.2.1 색상(Color)
적절한 색상 선택은 데이터의 구분과 패턴을 강조할 수 있다. 하지만 종종 시각화를 단순히 멋지게 보이게 하려는 목적으로 여러가지 색상을 사용하는 경우가 있는데, 분명한 목적이나 의도가 없이 색을 사용하지 않으면 오히려 혼란만 불러일으킬 수 있다. 마포구 반려동물 이름 순위를 시각화한 아래 두 그래프를 비교해보자.
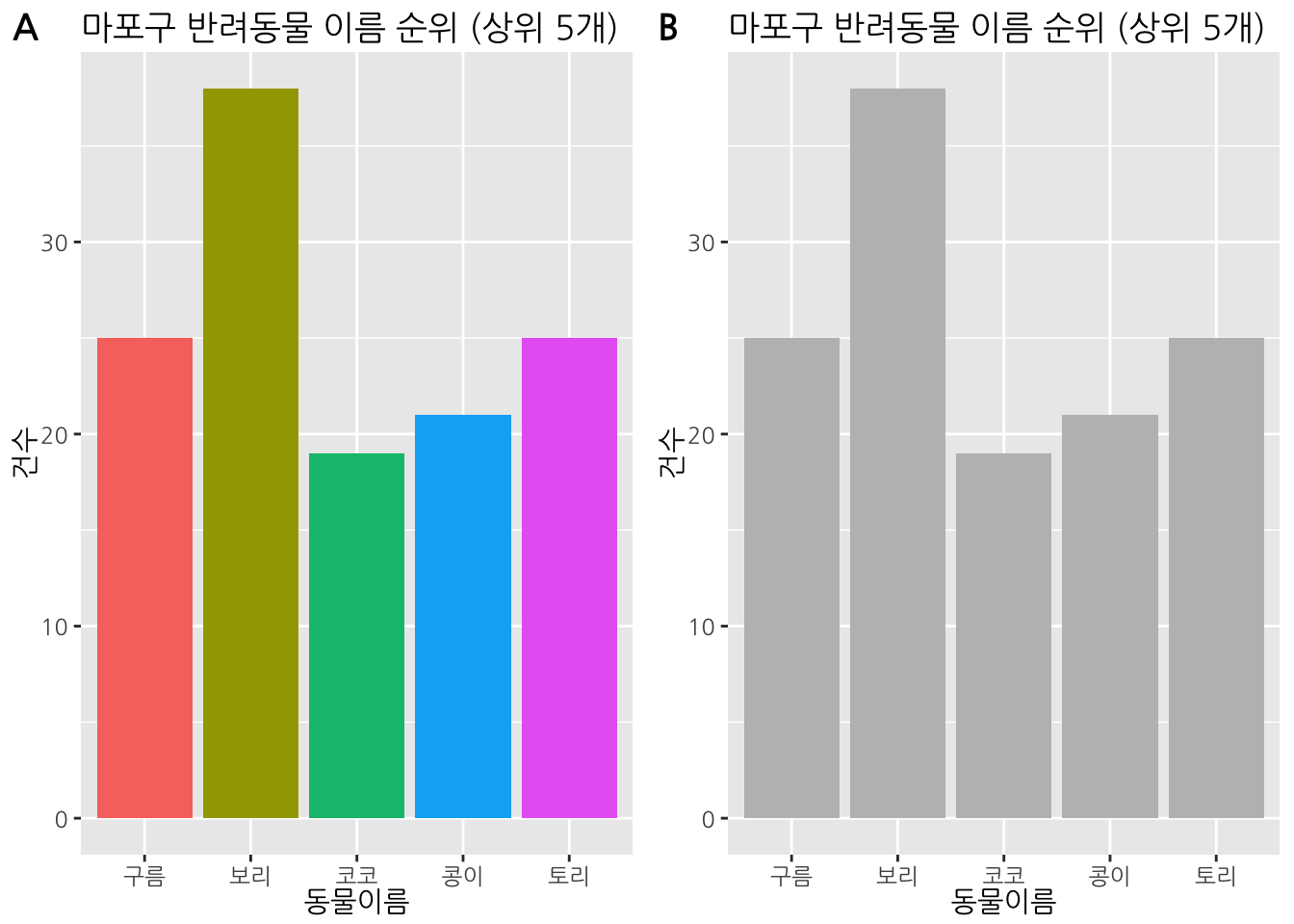
A의 경우 알록달록하니 예쁘긴 하지만 색이 무엇을 의미하는지 한번 더 들여보게 된다. 반면에 B는 조금 투박해 보일수도 있지만 전달하고자 하는 정보가 정확히 전달되는 데 아무 문제가 없다. 특별한 이유가 없다면 최대한 적은 색상을 사용해 안그래도 복잡한 이 세상에서 보는이의 피로감을 조금이나마 감소시켜 주자.
카테고리 별로 다른 색을 사용하면 보는이가 직관적으로 차이를 감지하게 된다.
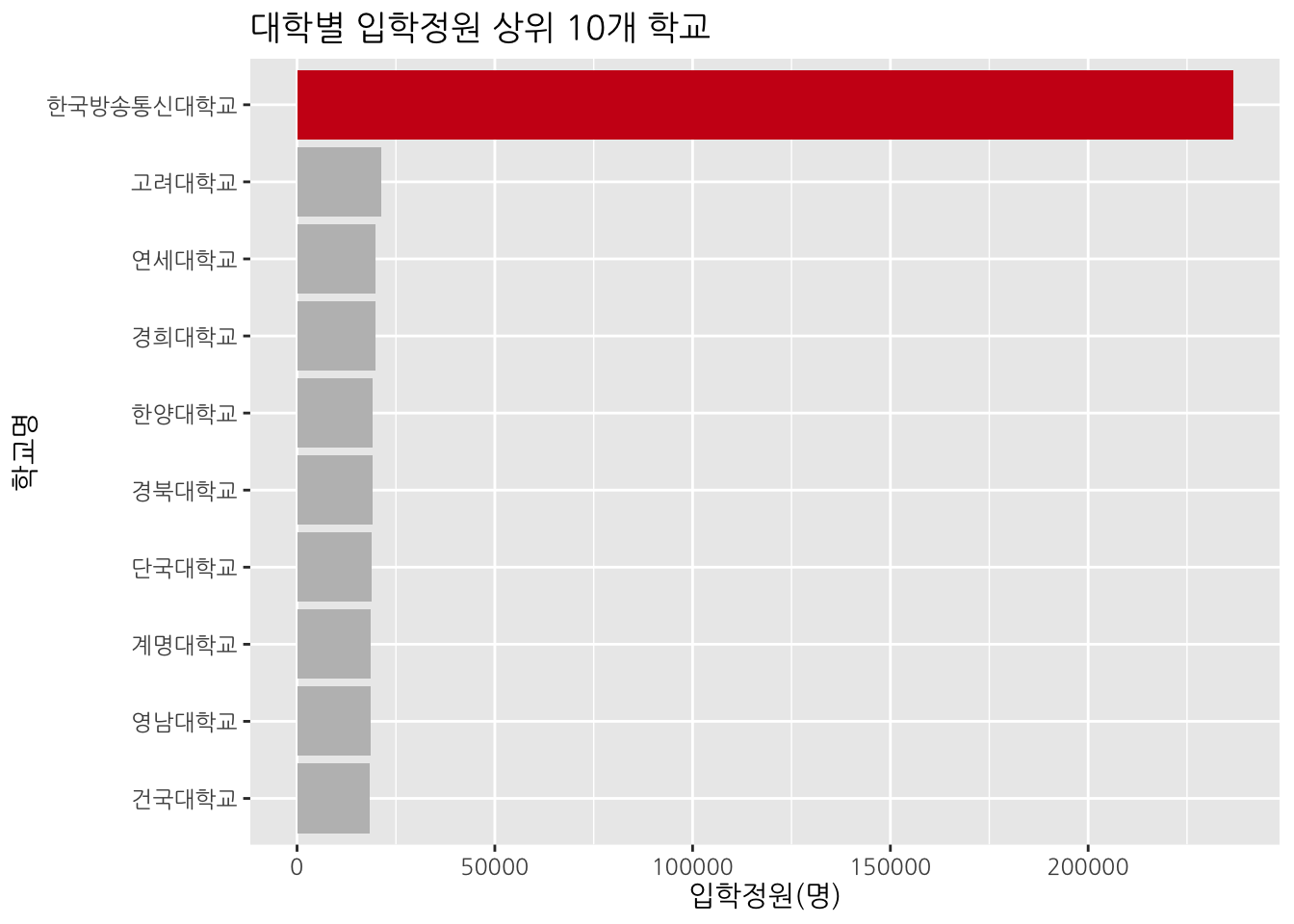
또는 강조하고 싶은 곳에 특별한 색을 사용할 수도 있다. 한국방송통신대학교가 압도적인 입학정원을 보인다.